Working from home isn’t all bad news. Picture my own.
I’ve been working from home for many years and I have to tell you that one major benefit is having your own space to work. My wife just bought me a ceramic-heated coffee coaster and I couldn’t be happier. It fits perfectly in it’s assigned space on my custom-made reclaimed wood standing desk, in front of my second monitor. Yeah, man. I’ve got it good. But it hasn’t always been this way.
In my line of work, I frequently work for new clients on a regular basis and therefore do not keep offices there the way I did fifteen years ago. Before I got my home office together, it was a itinerant life: carrying the only office I knew in a backpack from one client’s office to the next Wegmans cafe to the next library. Even long-term contracts never seemed worth setting up permanent offices at. It’s only been since I’ve taken the time to set myself up in a home office that I feel at home working anywhere.
Now, if you’ve just found yourself suddenly without access to your office, it may be too much to ask that you have a whole “office” to yourself at your house. And unfortunately, the vagabond life is also no good when you’re trying to keep some social distance. Nevertheless, the first thing you need is a spot to work.
You may not have a room that can be sacrificed. Maybe just a spot in the dining room. Or a bedroom. Perhaps a small, darkened corner where the kids never look for their toys is what you have. Ok, not great. But it’s something. Move in.
Get some office stuff, whether that means gathering up second-hand crap around the house or getting something from Amazon and having to wait. Pens, paper, stapler, tape. Sticky notes, a keyboard wrist rest; stress ball, your favourite hunk of lapis from the gem show, a USB-powered fan, a pair of decent speakers. Get it. And while your at it:
Get the good chair. You deserve it.
Phone access
Printer access
Fax access
Internet access
A window? Let’s hope so!
Just because you don’t “go to the office” does not mean you should not have a place to go. The separation between work and home continues to be very important and a physical distance helps. Let others know that the office is where you go to be alone with your work.
I’m a parent and don’t plan on spending a heck of a lot of time in my office, to be honest. If you’re a parent, you already know what I mean. But it needs to be there and it needs to be respected. Because when things about the job just require your undivided attention, you need that resource.
Now normally, these listical-type, inspirational posts like to end on that high note where you match a “go out there and get ’em!” type message, typically with a picture of someone either doing yoga on a beach or climbing a mountain, as suits the occasion. And that’s fine, as far as it goes.
But you’re not climbing mountains or doing yoga. You’re trying to keep it together whilst the world goes indoors to play. This is about helping you maintain your mindfulness and productivity while you “camp” at your house. So I’ll start with the 1000-mile view crap early, so you can ignore it at will.
Nevertheless, the fact is that you’re a productive member of society because that’s your natural state. Or, perhaps you’re a lazy-ass, because that’s your natural state. The point is: you will reach your natural level of productivity, one way or the other. The venue in which you produce your work will change; the means by which you communicate will change; you will not change.
“Everyday humor” about working from home – the kind of talk you hear around the water cooler – is as follows: “wouldn’t it be nice if I could go work from home!” / “If I worked from home, I’d get nothing done.” Neither of these two things is true. It’s not automatically nice to work from home. It’s also not the automatic path to lost productivity.
The point of this post is to simply tell you – for sure – that you’re going to find working from home very productive. Not necessarily easy or enjoyable for everybody. But it will be productive. Have faith!
So you’ve just gotten the word: you’re gonna be stuck in the house for a bit. COVID19’s cloud has reached your town or city, a state of emergency has been called and you’ve been asked to practice “social distancing” in an attempt to prevent the further spread of the virus. Of course, none of us wants to be sick, so we do as we are asked.
In the meanwhile, it may feel a bit selfish to be inconvenienced by a pandemic. Some things feel trivial. Our world is in the throws of a major, species-wide crisis and now may not seem like a good time to think about anything other than the very basics.
Work, for example. Some of us will simply not be able to work, at all. How we keep the trains running in those houses is an answer still to be determined. Those of us for whom remote work is possible will just need to muddle through. No sense in making a big deal about it: we’re the lucky ones.
But working from home represents a pretty big change in your routine, even in non-pandemic circumstances. I made the commitment, years ago, that I would do my best to find a career path that included working from home. At the time, I wanted to be available as a more active father in my then-future offspring’s life. But if I’m being honest, I just wanted to work from home because I thought it would be pretty cool.
After all: as a developer, my job requires me to spend time focused on code on a machine. Much of my time is insular by design, spending focused intervals carefully picking through lines of code or pouring over documentation. One might suspect that an employee in my profession could work all day without the slightest interaction and do their jobs just fine.
One would be wrong. I learned through experience that it takes more than a convenient job to make working from home a success. It requires self-discipline, for a start. It also requires a realistic view of work life which doesn’t prejudice your idea of what a day’s work looks like.
And while some jobs require less conversation to be successful, there is no one who “doesn’t require social interaction.” Least of all you! Finding ways to be social without direct, face-to-face contact is important. And even if you’re not “going to work,” that doesn’t mean you don’t need a place to work.
On the other hand, some of the rumors are true: we really do work in our PJs. All the time. Lunch is way better with your entire kitchen at your disposal; breaks are way better with Star Trek to watch on your big, old flatscreen. And if we’re being honest, some of our coworkers’ personalities can only be enhanced with distance.
My wife is a secondary education teacher. She’s home because our state and county are in a state of emergency and the schools are closed. Not only does she need to teach kids who are now across town, but we both need to share the responsibility for continuing our own son’s education. All while managing to keep ourselves sane and functioning as professional adults. It struck me while discussing our shared family predicament: a lot of people could use some hints on how best to manage just the business of working from home.
Sadly, managing our professional lives is a low priority. We have families to look after and houses to keep up. But in the coming days, I’m going to provide a quick list of insights I’ve gained from being a work-from-home employee that might just help curb the uneasy feelings you have while trying to balance work priorities with family ones.
Don’t worry: this won’t be one of those things were I do the “drip content” marketing jazz. I’ll be writing these as I’m able to. And they’ll probably be shorter than this one introduction. I hope you get some useful information from this series! I’ll keep a running list below:
One of the most important concepts in the world of WordPress web development is that of the parent/child relationship between themes. The parent/child relationship is a scenario in which a “parent” theme represents the final source of all code: if you cannot find a given file in a theme declared a “child” of one parent, then you should be able to find that file in the parent. The purpose of this relationship is to allow the child theme to extend and enhance the parent theme as suits a given website’s needs, while still maintaining the base level functionality of the parent theme. This failover system further augments WordPress’s excellent Template Hierarchy structure, guaranteeing a suitable template layout file for any request.
When properly understood and executed, this parent/child relationship allows developers to build complex parent themes from which all manner of new websites can be built in the child theme. Doing so is a sure-fire way to maximize the learning curve of your software: new techniques and interfaces can become available to the next project, instead of stuck in a single-site solution.
In my case, my parent theme is really just a toolbox of functionality and layout helpers with almost no usable layout of it’s own: it provides the toolbox and a few baseline layouts like a generic archive and single-post page. All the implementation of that toolbox happens in the child theme. I have even augmented the parent/child relationship a bit by providing failover support for JavaScript files and non-layout files in my theme.
That said, I’m always looking for better ways to make use of this relationship. So I was pretty excited when I found out that Advanced Custom Fields comes with the option to save it’s field declarations as local JSON files. I’d previously been doing all the work of creating Custom Post Types – and their backend interfaces – more or less by hand. But having worked with ACF for a bit, I realized it was a more efficient means of adding meta fields by miles.
Now it seemed, I’d found a way to statically create the fields I needed for my base CPTs and have them extend and be extended by a child theme. Perfect!
Not So Perfect, Yet.
Now, I’m pretty particular about my directory structure for my plugins. I like things organized more like the PSR2 standard prefers and fortunately, the WordPress-Core standard also recommends something similar. With that in mind, ACF’s default location for local JSON does not suit me. I’d rather not have an /acf-json directory in the root of my theme. Instead, I’d prefer to have my ACF-specific JSON files live somewhere in the /Library/ directory of my theme.
But there is a solution for this! Advanced Custom Fields provides filter hooks in that part of the code that saves and retrieves JSON, as they explain in the documentation for local JSON. Those hooks are ‘acf/settings/save_json’ and ‘acf/settings/load_json’. So my first attempt to move the JSON to my desired destination looked like this:
The persistent problem I ran into with this setup was that ACF seemed always to be confused as to which directory it should be saving and recalling from. If you read through that code, it at least attempts to establish the same parent/child relationship as WordPress uses for standard template files. New changes to Custom Fields should always be stored in the current (most often, the child) theme directory. When pulling JSON to populate fields, a child theme’s /Library/Acf-Json folder should be used first, followed by the parent theme.
But in practice, after successfully changing a field name in a child theme, the Custom Fields admin pages would show the correct new name and the Write Post screen would display the old name. Those fields did not present the option to “synchronize” themselves, so there seemed to be no real fix. This was all discussed with the forum help at ACF here.
After a bit of digging and considering and reading the actual ACF files in question (/advanced-custom-fields/includes/wpml.php, if you’re interested), I decided that rather than simply add my own code to the acf/settings/save_json hook, I would remove the default function completely. By doing this and using array_push to be sure I was saving the directories in the correct order, I was able to achieve the the correct functionality. So I commit this blog post for the benefit of those who find themselves similarly challenged by this super-helpful but perhaps less than well-documented feature of Advanced Custom Fields:
The WordPress Customizer is an important part of the toolset of any developer who maintains their own custom base theme, whether we use that theme for projects or offer it up for sale. But I find there is a bit of a bedeviling problem with the Customizer and default theme modifications (theme_mods). Basically: there’s no built-in solution for them.
Consider the following scenario: a theme uses a scaffolding framework like Zurb Foundation to produce completely-custom layouts, and therefore does not have a “base state,” as would be present with most commercial themes. In commercial theme sales, the idea is to create a theme which is hopefully 80% of the way to someone’s perfect website. A developer then buys the theme, making small adjustments in a child theme to cover that last 20%.
But this theme is a toolbox aimed at providing unlimited layout options. If I want a horizontal-stripe layout for one page and a standard blog header/footer/content/sidebar layout on another, this theme will allow it. There are no assumptions as to what you’d want out of the theme. As such, in order for the theme to present ANYTHING on the front end, it’s going to need some default mods. Actually, rather a lot of them. But the solution is pretty simple, in theory: just load a default set of mods if nothing has been saved in the Customizer.
Here’s where it gets tricky: unless you’ve modified a value in the WordPress Customizer, it does not save to the theme mods for the theme. So if you open a WordPress Customizer, change a few values, then hit “Publish”, those mods and ONLY those mods would get saved to the database. That makes life difficult if you’re looking to quickly check to see if anyone has modified the theme as in the above scenario.
Digging around, I discovered that the WordPress Customizer ships with a number of filters. But for our purposes, there is the customize_save hook, where we will insert our own check for default values:
Those of us who remember suffering through Subversion repository woes will remember our elation at finding Git. Things Subversion promised but never quite delivered were handled with ease when we got to Git. Merging changes? Updating branches? Rolling back changes?? All a snap.
But there are some subjects on which I confess I have adopted the “we’ll get to that particular voodoo later” attitude. One of those was figuring out what the difference between git merge and git rebase. I shan’t bore you with that whole story: Google answer-seekers, rejoice! Instead, here goes:
The difference between git rebase vs merge is the commit history.
If you rebase a branch from it’s source (feature branch from master, let’s say), none of the commits from the source branch will show up in the feature branch’s history. If you merge the two branches, you will have both branch’s commits in the source branch.
The result of merging therefore is a commit history that includes a lot of work that did not happen in the current branch. The result of rebasing is a commit history that does not include changes that have recently been added to the current branch from elsewhere. Both of these scenarios have advantages and disadvantages.
Rebase feature branches, merge master
Sure. There’s lots of nuance to this kind of broad-strokes pronouncement. I encourage you to read this article, which has so far been the best tutorial on the subject that I have read. But for brevity’s sake, in probably 90% of cases, the above statement is your best guide.
Feature branches should presumably have lots and lots of commits. Personally, every time I think I’ve got a feature or bug “fixed,” I end up committing that new change right away. Yes, it makes for a lot of logs. But it also means the exact moment when a file got changed is much more reliably pinpointed.
If I were to merge my master branch into my feature branch, I’d also have all the commits to master from other developers mixed up among my branch’s commits. File changes that have nothing to do with my feature would appear as their own logs. For this reason, I’d rather just have my feature branch focus on the work that I did, with commits that match.
When I bring changes from a feature branch into master, I actually do want the small changes and logs to appear in the master branch. I may need to track a specific file change, and the feature branch will soon be either destroyed or archived. Incorporating a feature branch’s commits helps me do that.
Git rebase vs merge: the advantage
I’m assured that feature branches contain logs that only concern that branch by rebasing changes from master into them. I am assured that all that work from all branches will be reflected in the master branch’s logs by merging changes into master.
Hopefully, this discussion of why you would use git rebase vs. merge was helpful. Do you have another theory for managing these two features? Please comment below!!
Hello, non-coder person! If you are not a developer and clicked on this article anyway, thank you! This article is definitely aimed at you. I’m a firm believer in cross-pollination and synergy among different disciplines and to that end, I have written this article to provide a bit of insight into the world of logic as developers see it on a daily basis.
My hope is to illustrate a fundamental concept in development that is important to all of us who rely on our work being correct, timely and self-evaluating. It is my intention to explain something in pseudo-coding terms that provides immediate value to all Agile teams. Understanding the nuances of logical decision trees like those developers create can help improve the way we organize our projects, communicate our needs and execute our tasks on a daily basis. Follow along, won’t you??
And if you like this article, please have a look at my developing Agile article series, Continuous Learning Curve!
Wanted: True or False
The most basic concept in the world of coding is logic, and logic is binary. Statements can either be evaluated as true, or as false. There are no “maybe’s” in logic. It is a world of seeming perfect bifurcation: true and false, one and zero, on and off.
One might think that a binary system’s best expression would be a perfectly-bisected world: a world in which concepts evaluate as true as often as they do false. One would expect code created in this world would work as effectively on both sides of the boolean divide.
But that seeming clarity hides a world of complexity, as new developers quickly discover. Nothing about the duality of logic creates a truly binary system, because the concept of false encompasses a world of bad options much larger than that of true: anything in the world other than true is false.
Should I Stay or Should I Go (a boolean example)?
Consider a simple mathematical equation: 2 + 2 = x. If I were to tell you that x was 4, that would be true. But every other number you can think of is false. So to would be every alphanumeric character, punctuation mark and combination of characters. The number of true statements (1) is vastly outweighed by incorrect statements (∞-1).
Fig. 1 – Save this image and take notes. This is important. source:imgur.com
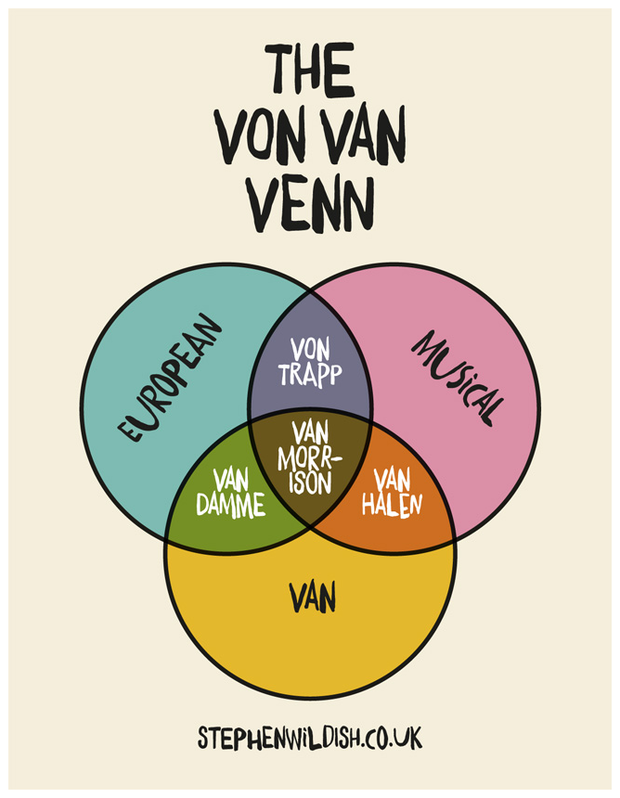
Of course, that is a simple example. As a slightly more complex example, consider the Venn diagram to the left.
How would we construct a logical statement from this diagram that could evaluate to true or false? Well, what if we were to ask “Is a Van musical?” The human answer is “maybe.” And the answer is a maybe, based on other data: is the Van in question a Van Halen, or some other type of Van? Because if it’s a Van Damme, well, that’s not musical at all, according to the chart. A computer will therefore evaluate the answer as “false,” because simply being a Van is not enough to be musical.
Yet in this more complex example, the ranges of potentially true and false statements are much narrower and much closer to equal than in the simple algebraic one. We do not have a single right answer and because we are bound by three domains (European, Musical and Van) we do not have an infinite number of answers, either. We do have answers that are partially correct, and evaluating the veracity of any statement based on this example gets trickier.
Most Musical people and European people are not Vans, but even most Vans are not Musical. Meanwhile all intersections between the Musical and the Van circles – including that section where all three circles intersect – evaluate as true. We’ll call that center bit the “Van Morrison Zone.”
Decisions in the Boolean World
Decision making code illustrates this concept of unequal evaluations. The example below is the most basic logical decision maker, the “if/else” evaluation, and contains within it the central paradox of logic. In this evaluation, we ask the system to evaluate if a statement is true. In that case, we execute the block of code just below the if clause. If the statement evaluates false, we execute the block of code after the else keyword.
This is among the most basic of code concepts. New developers often use this idiom to create logic trees that treat if and else as equals. The developer evaluates a statement and based on its truth or falseness, takes the next step in the process. We could for example evaluate whether x in our first example equalled 4, continuing on with the script if true or generating an error if the answer is false.
But as we see in our second example, not all decisions can be made in a single evaluation. We combine two evaluations into a single clause and only if both evaluations are true can we arrive at a true statement. Critically, we arrive at a clause that treats the if and else clauses differently: the if clause treated not only as the true clause, but also as the more specific clause:
The Principles of Boolean Thinking
So what is the upshot of all this boolean determination? Does the fact that false represents a larger subset than true mean anything practical in the real world? How can we improve the way we approach projects and communication better by understanding this idea? Here are a few very important take-aways:
While true and false represent two subsets of an entire range possibilities, if and else clauses yield only two actions with which to treat the subsets.
Because we can evaluate a statement true only when we can specifically identify it as true, that subset of possibilities includes statements about which we know a lot.
Because anything that does not evaluate to true is therefore false, we know relatively little about this set. We cannot assume anything about this result set, including whether the statement exists within the range at all!
That last bit is important to understand: while our Venn diagram was a closed system, most things in life exist out in the open, in the midst of a nearly-limitless set of possibilities.
This all adds up to a basic tenet: else statements are inherently weak and unreliable. Contrary to our original assumption, code does not work as effectively on both sides of the boolean divide, at all. We cannot know anything with certainty about else statements, therefore what we do with those statements must be limited and generic. The only place for an else statement to lead is either an error or else a new interrogation, altogether. But one way or another, you just can’t trust ’em.
In Agile development, we are trained to tell stories about the work we need to get done. “As a [role], I need [goal] so that [reason].” Taking that idea one step further, we can describe our desired result as a simple if/then logical tree to better understand the relative complexity of our request.
Let’s walk through a set of Story statements to see how this might work.
I’ve been a big fan of Zurb Foundation for quite a while. So much so, that every WordPress project I’ve created in the last six months (about 40, all tolled) have been built using my Foundation 5-based theme, HN Reactive. The new version of Foundation has had me itching to start developing, but I’m presented now with a problem:
The production server where I house my clients’ projects has tons of projects that rely on Foundation 5. But Foundation 6 is significantly different from 5 that they’re not at all compatible. Worse, since both versions want to use the name “foundation” as their function name, they step on each other. So, how can we use Foundation 5 and 6 together?
It is true that the only reason to use the “foundation” command with 5 is usually to create a new project. You could probably continue to use Compass to compile existing Foundation 5 projects while using the Foundation 6 version to create new projects. But that is a wholly unsatisfactory position to put myself in, on the off chance that an installation of 5 needs to be rebuilt for some reason or another. And there’s no way I’m putting myself in that position on a production server where a lot of people are paying me money not to have such problems.
Zurb Foundation 5 and 6 together:
After searching for a solution and finding none, the solution ends up being aliases. By creating an alias record in your shell profile (.bashrc or .bash_aliases in Ubuntu), you can all live together in one happy, productive family:
Late Update: it appears based on further research that a recent update of Foundation 5 ended up putting that executable in the same place as F6. So with this in mind, I recommend:
Install Foundation 5
Move the foundation executable from /usr/local/bin to /usr/bin
I wanted to have a word with you about your website. You know, the massive data structure that combines text, audio, video and images all in the pursuit of explaining what it is you do and how your customers can find you. Yeah, that thing.
Does it not strike you as wholly silly to have an “About Us” page on such a thing? Isn’t the entire site, you know, about you? Is there something you really need your audience to know about you that isn’t somewhere else on the site? And is that a good idea?
Some conventions of the Internet exist almost completely without cause. They’re just things we’ve grown accustomed to seeing and feel weird about not having. The “About Us” page is top of that list, in my opinion. Unless you run something like a media site – and maybe not even then – there is nothing about you that doesn’t deserve equal time with the rest of your marketing content. In fact, your marketing content should be shot through with all those most important things about you that make you different. Or special. Or just happy to be alive. But it doesn’t belong on one lonely page that nobody will bother with.
Frequently, when designers I work with spec out pages, I’ll tell them to just kill the About Us page. Make an About link in the navigation if you have it, but link that to the front page. Why waste the effort on a vestigial page?
If you’re looking to use Zurb Foundation for WordPress layouts (hint: you should totally be using Zurb Foundation for WordPress layouts), you’ll probably want to create a fluid, responsive footer that is horizontal for desktop but vertical for everyone else. How do you go about such a thing? Bon apetit: